Home Page












Weekend Deals: Up to 40% off select products






Marketing & swag to draw in a crowd






Celebration essentials for every occasion
See all celebrations







Stock up & save on business essentials









Tools to help build your business


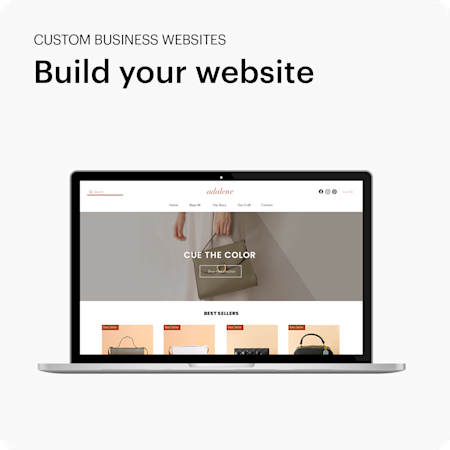
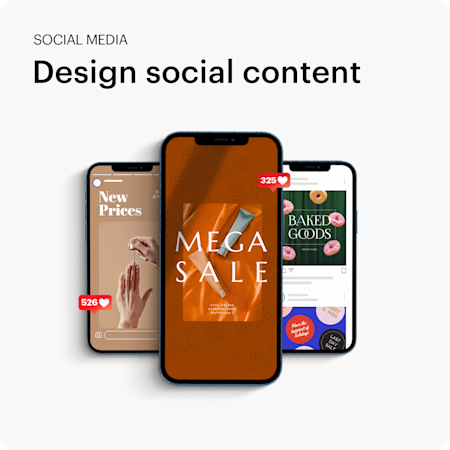


Our online tools make the process as simple and clear as possible, and we’re working to improve your experience all the time.
Our designs can be used across multiple printed products, which makes it easier for you to create consistent, professional marketing.
Made by you, #MadeWithVistaPrint
We love to see your custom creations. Post a photo on social media and add @VistaPrint and #MadeWithVista for a chance to be featured here.